
Did you know that there is an easy way to shape your data in Fabric Notebooks using Data Wrangler?
I was going through my twitter feed and I came across this tweet where they spoke about the Data Wrangler Calling all #Python users! Have you tried Data Wrangler in #MicrosoftFabric?
I thought I would give this a try and that was the idea for my blog post. I honestly had no idea that firstly was this possible, but second that it is so easy for data wrangler to do all the hard work for me
I am going to demonstrate 2 transformations in this blog post, the first will be changing the d_date from date to datetime and then using the columns from examples I am going to create a new column where it concatenates 2 columns delimited with a double pipe command.
I liken the data wrangler in notebooks as what we have in Power Query in Power BI.
I am very new to notebooks and the new associated language so I apologize in advance if there is any easier way to get this done, if there is please let me know in the comments!
The first thing to point out is that to use the Data Wrangler it must come from a Pandas data frame.
SIDE NOTE: In my mind I think of a data frame as a table!
I uploaded some sample CSV Files which had some basic flight data about delays into my Lakehouse. This is what the CSV file looked like below.

The next thing I wanted to figure out was how to load multiple files from a folder. As very often there is not a single file but multiple files.
I found this blog post which helped me get the code I needed: Pandas Read Multiple CSV Files into DataFrame
Using the code from the link above I then modified it so that I could read the CSV files from the Lakehouse.
# Import libraries import glob import pandas as pd # Get CSV files list from a folder path = '/lakehouse/default/Files' csv_files = glob.glob(path + "/delays_*.csv") # Read each CSV file into Panda DataFrame # This creates a list of dataframes df_list = (pd.read_csv(file) for file in csv_files) # Concatenate all DataFrames big_df = pd.concat(df_list, ignore_index=True) #View the Panda dataframe display(big_df)
Some additional details where I had to modify the code.
-
LINE 6
- In order to read the files, I had to put in the full path from the LakeHouse
- NOTE: I had already selected my Lakehouse in the Lakehouse explorer

-
LINE 7
- This is where I filtered to only load my delays CSV Files
-
LINE 18
- I always like to view the data to make sure that it is showing the expected results as shown below.

- I then had to run the cell to load the DataFrame

Now that I had created my pandas data frame, I then clicked on Launch Data Wrangler

I then waited while it searched my notebook for the pandas DataFrames

NOTE: If it does not find the DataFrame make sure to run the cell to load it into the notebook.
I could then select my DataFrame called “big_df” from the code above.

This then opened the data wrangler, which then loaded the data with some details as shown below.

On the left-hand side are the operations which can be done to the data.

In my working example I am going to update my column “d_date” to Date Time and to be called Date_Time and then create a new column based off examples.
To change my column called”d_date” I expanded the Schema and selected “Change column type”

Then in the Change Column Type I selected my column called “d_date” and then selected the New Type to be “datetime64[ns]
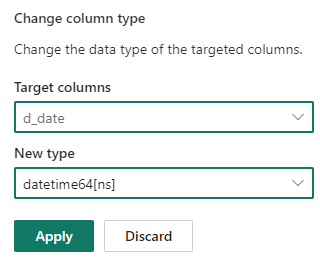
In the table view I could see the proposed changes (which is great to see if it what I am expecting)

I then clicked on Apply.
I could then see the step below in the cleaning steps.

The final transformation that I am going to do in this blog post is the concatenation of the two columns.
Under Operations I clicked on “New column by example”

Next, I had to select the target columns, which is the columns I want to use generate my new column from

Then in the Derived column name I put in the name of “Origin_Destination”

Now to create the column by example in the data pane on the right-hand side there is a new column which is highlighted in green but has no data.

I then clicked into the first row, which then prompted me to Enter an Example

I then typed in “ANC||SEA” and waited a few seconds. After which I could then see result in the additional rows.

Now under Operations I had the option to click Apply.

I could then see the step below in the cleaning steps.

If I wanted to change anything I could click on the cleaning step and make an edit.
I was now happy with my data wrangling, so I clicked on Add code to notebook on the top right.

When the notebook loaded, it then automatically inserted the code and ran it, and I could immediately see my results below.

How awesome is that!
My final step was to convert the pandas dataframe back to a Spark dataframe and create the delta table which I did with the code below.
#Convert pandas dataframe from back to a Spark dataframe
sparkDF=spark.createDataFrame(big_df_clean)
sparkDF.show()
#Write to Delta Table
sparkDF.write.mode("append").format("delta").save("Tables/Delays")
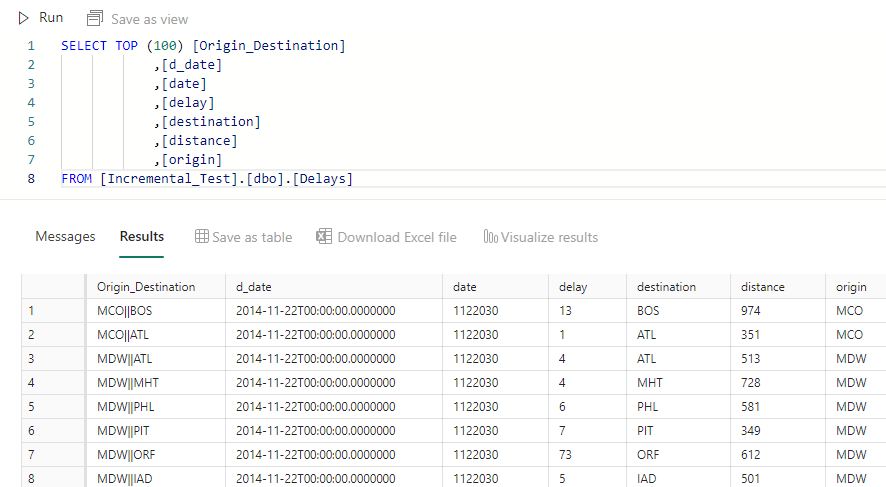
I could then go into my LakeHouse and view the “Delays” table using the SQL EndPoint.
Summary
I hope that you found this blog post useful on how easy it is to transform your data with the data wrangler in Fabric Notebooks.
Any comments or suggestions are most welcome. Thanks for reading.
[…] Gilbert Quevauvilliers tries out a tool: […]
[…] I had previously blogged about using Pandas data frames but this required extra steps and details, if you are interested in that blog post you can find it here: Did you know that there is an easy way to shape your data in Fabric Notebooks using Data Wrangler? […]